큐브리드의 QA 절차 및 업무 방식에 대해 소개하겠습니다.
CUBRID QA팀이 하는 일?
QA(Quality Assurance)팀은 CUBRID의 품질 보증에 대한 전반적인 절차를 다루는 업무를 맡고 있습니다. 단순 테스트뿐만 아니라, 개발 프로세스에 직간접적인 관여와 QA Tool 확장 및 유지보수, 제품 결함 관리, 제품 릴리즈 등 제품이 출시되는 과정에서 여러가지 일을 하고 있습니다.
특히, 개발과정의 처음부터 끝까지 참여하여 품질 저하에 문제가 될 만한 부분이 있는지 검증하고, 개선안을 제안하는 등 개발 프로세스 전반적으로 개입하여 제품 품질을 높이는 일을 하고 있습니다.
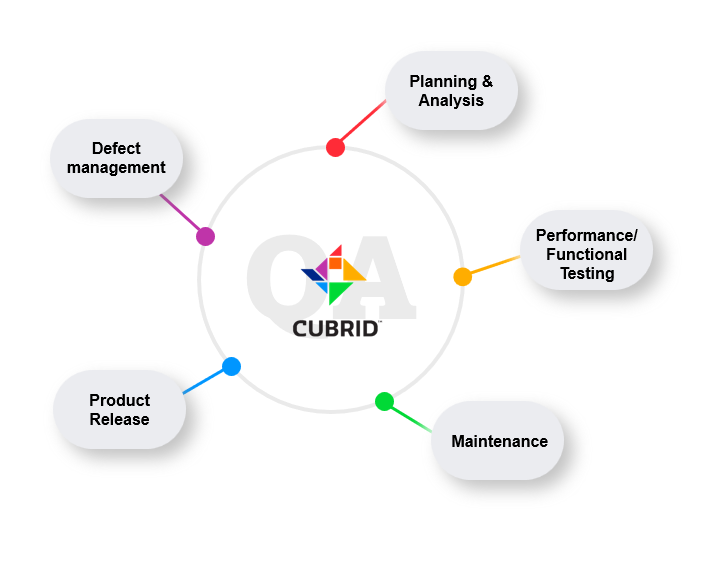
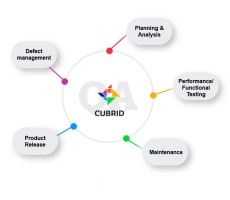
CUBRID QA 절차
CUBRID QA 절차는 크게 다음과 같이 볼 수 있습니다.
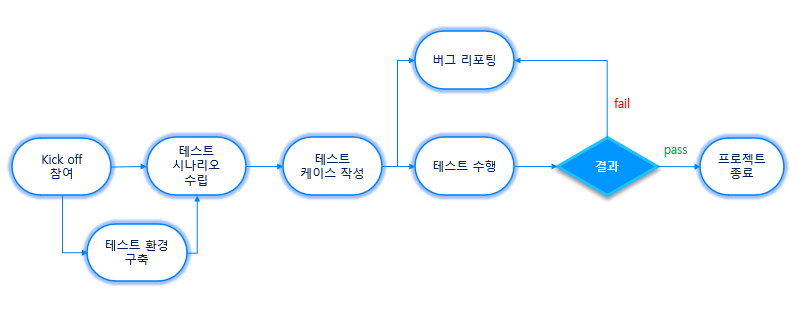
각 절차에 대한 상세한 과정은 다음과 같습니다.
1. Kick off 참여
- -먼저, 개발팀으로부터 프로젝트를 할당 받으면, 킥오프를 참여합니다. 요구사항 및 목표를 파악하고, 사용자 관점에 부합하지 않을 경우 개선을 요청합니다. 프로젝트에 따라 검증방법이나 절차가 달라질 수도 있고 때에 따라 새로운 환경이 필요할 수 있기 때문에 여러 가지 의견들을 종합하여 팀 내 담당자를 선정합니다.
2. 테스트 환경 구축
- -프로젝트를 위해 어떤 테스트가 필요한지에 대한 분석이 끝났다면, QA를 진행할 환경을 구축합니다. 만약 기존 구축되어 있는 테스트 환경이 요구사항을 충족시키지 못한다면 직접 환경을 설정하여 테스트를 수행하거나, 직접 테스트 프로그램을 만들기도 합니다. 제작된 테스트 프로그램이 장기적으로 유효한 테스트라고 판단될 시 regression test에 추가합니다.
3. 테스트 시나리오 수립
- -프로젝트가 진행되면서 사용자 예상 시나리오를 수립합니다. 일반적으로 테스트 시나리오는 유효한 입력을 사용한 긍정적 테스트와 유효하지 않은 입력을 고려한 부정적 테스트를 고려합니다. 그러나 비정상적인 상황은 너무나 다양하기 때문에 현실적으로 모든 부정 테스트의 시나리오를 수립하고 자동화하여 테스트하기는 불가능합니다. 때문에 최대한으로 다양하고 확장된 시나리오를 수립하는 것을 목표로 합니다.
4. 테스트 케이스 작성
- -사용자 시나리오 수립이 완료되면, 시나리오를 검증하고 테스트 케이스를 작성합니다. 이때, 문제점이 발견될 시 JIRA에 보고합니다.
- -테스트 케이스는 SQL문으로만 이루어진 경우엔 SQL 테스트로, CUBRID 유틸리티나 프로세스 제어, 사용자의 동작 등이 테스트 시나리오에 포함된 경우는 shell 테스트 케이스로 작성하게 됩니다.
- -SQL, shell 테스트 이외에도 요구사항 목적에 맞는 테스트 프로그램의 테스트 케이스로 작성하게 됩니다.
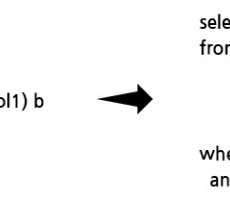
다음은 간단한 SQL 테스트 케이스와 답지의 예시입니다.
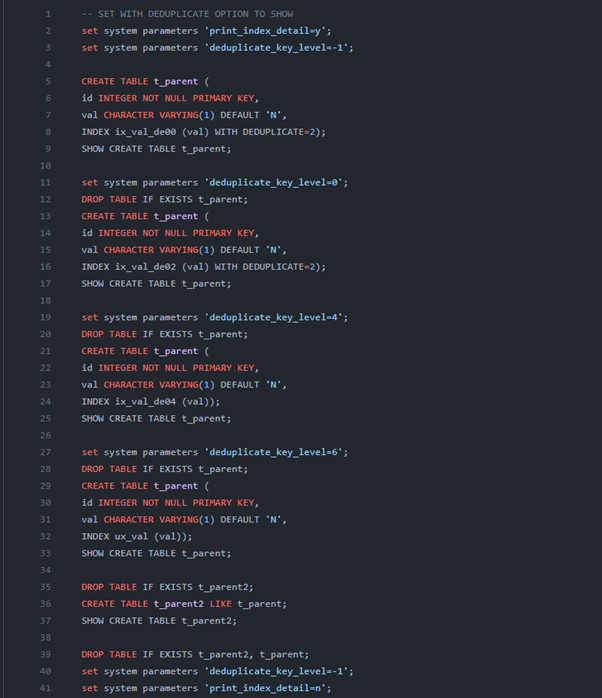
sql 테스트 케이스 예시) cubrid-testcases/sql/cbrd_24478/deduplicate/cases/02_create_table1.sql
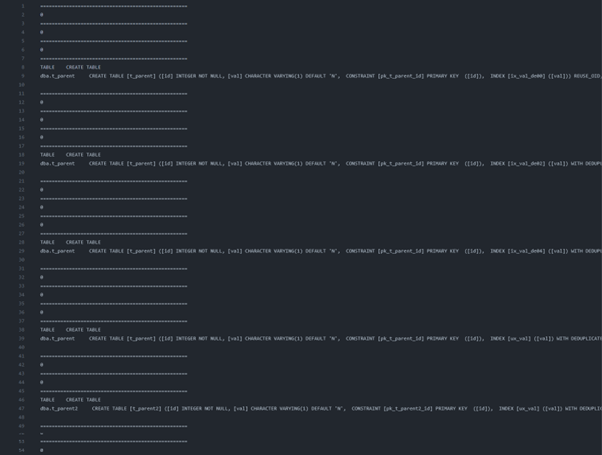
sql 테스트 케이스 답지 예시) cubrid-testcases/sql/cbrd_24478/deduplicate/answers/02_create_table1.answer
5. 버그 리포팅
- -만약 제품 내 결함을 발견했다면, 버그 리포팅을 진행합니다. 버그는 보통 테스트 시나리오를 검증하는 테스트 케이스 작성 단계나, 테스트 수행 단계에서 주로 발견됩니다. 개발자와 구두로만 소통할 시, 히스토리 관리가 매우 어렵기 때문에 JIRA를 이용하여 기록을 남기는 것이 중요합니다.
- -버그리포트에는 core가 있다면 call stack 등의 core 정보, 테스트 버전, 재현절차, 기대결과, 실제결과 등의 내용이 포함됩니다.
6. 테스트 수행
- -작성된 테스트 케이스는 Regression test에 포함됩니다. Regression test 결과를 분석하여 새로 작성된 테스트 케이스의 결과가 통과하였는지, 그리고 기존 제품의 영향도나 버그가 있는지 확인합니다.
7. 프로젝트 종료
- -이슈가 발생하지 않았을 경우, 프로젝트를 종료하고 결과 및 관련 내용을 JIRA를 이용해 기술합니다.
각 프로젝트들은 이러한 과정을 거쳐 QA의 검증이 완료되면 계획된 하나의 버전으로 빌드 및 배포가 이루어지게 됩니다. 또, 배포 이후 발생한 문제점이나 제품 성능 등에 대해 신속히 대처하여 추가적인 버전 관리를 수행합니다. 이처럼 QA팀은 프로젝트 기획 단계부터 시작하여 릴리스 하기까지 비즈니스 리스크를 줄이면서 최대한 이상적인 제품을 제공하기 위해 개발팀과 상시적으로 교류하고 더 나은 방향을 제안하고 있습니다.
CUBRID QA TOOL
CUBRID QA팀은 자체적인 QA솔루션 툴인 CTP(CUBRID Test Program)를 사용하고 있습니다. 효율적인 QA를 위해 이 툴을 사용하며, 자동화된 Regression test 수행 및 QA home을 통한 결과를 확인을 할 수 있습니다. 확인 중 발견된 버그는 JIRA(=Bug tracking system)를 이용하여 관리합니다.
1. QA HOME
먼저, QA home에 대해 자세히 알아보겠습니다. QA home은 Regression test나 커버리지 테스트가 수행되었을 때, 테스트 결과를 관리 및 공유할 수 있는 웹 페이지입니다. 개발팀에서 수정한 코드가 commit되면 자동적으로 Jenkins에서 CUBRID 빌드가 진행되며, 빌드가 성공적으로 완료되면 regression test를 수행하게 됩니다. 테스트 결과는 QA home 웹페이지와 연동되어 있어 히스토리 추적 및 관리를 용이하게 할 수 있습니다.
Regression test에는 sql/medium 등 개별적인 동작 기능이 미리 정의된 사양을 준수하는지 테스트하는 functional test 와 YCSB, Sysbench, HA Replication Delay Time, DOTS-Stress, TPC-W, TPC-C 등 안정성, 신뢰성과 같은 성능을 검증하는 performance test로 이루어져 있습니다.
1-1) Functional test
다음은 Functional test의 결과 페이지입니다.
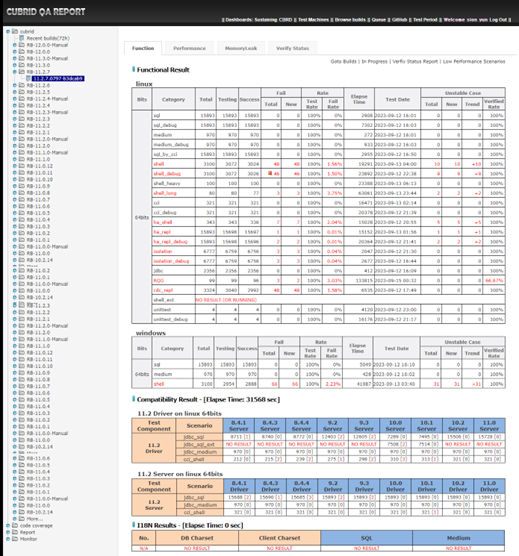
qahome 웹페이지 화면
Functional test에서는 Fail이 발생했을 경우, Fail count 숫자를 클릭하면 아래의 화면과 같이 테스트케이스의 실패 내역 리스트가 나옵니다.

qahome fail case 화면
Case file 리스트에 있는 테스트케이스를 클릭하면 테스트의 결과내용을 좀 더 자세히 볼 수 있고, 이 정보를 토대로 왜 테스트가 실패했는지 분석합니다. 실패의 원인은 다양합니다.
첫째로, 답지의 수정이 필요한 경우입니다. 최근에 개발팀에서 의도하지 않은 통계 업데이트를 막고자 ‘UPDATE STATISTICS’ 구문으로만 통계 업데이트가 되도록 하는 기능이 추가되었습니다. 그로 인해, show index 구문이 들어간 테스트 케이스들의 답지에서 통계 부분이 달라지는 현상이 있었습니다. 테스트 케이스들은 Git에서 각 테스트 별 레포지토리로 관리되고 있으므로, 해당하는 레포지토리에 직접 답지를 수정하여 pr(pull request)하고, 담당 개발자 및 QA팀원들의 리뷰를 거쳐 병합합니다.
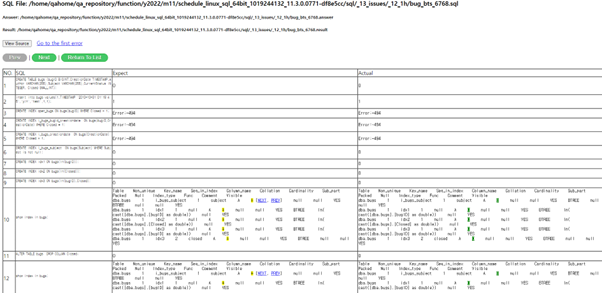
QA home Fail case 상세결과화면
둘째로, 버그일 경우입니다. 다음은Isolation test에서 public 유저로 서브 쿼리를 실행했을 때 성능 저하가 발생하는 현상을 JIRA에 보고한 예시입니다. 버그일 경우에는 담당 개발자가 JIRA 내용을 보고 분석하여 해결하는 과정을 거칩니다.
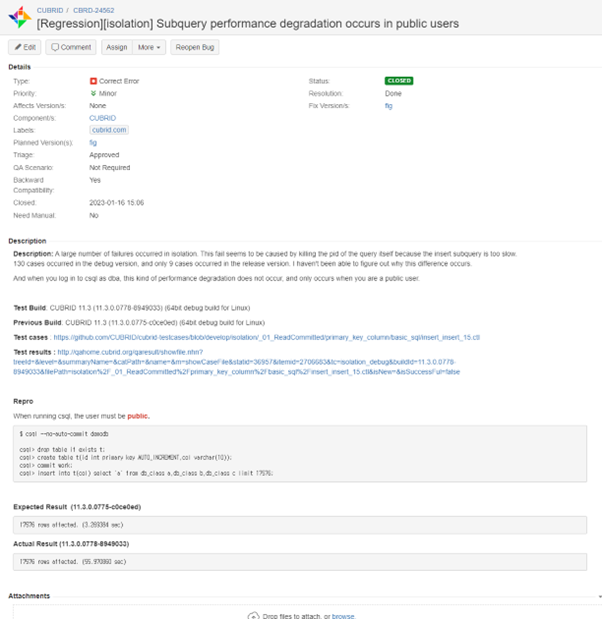
JIRA 버그리포팅 화면
추가로 Core가 발생했을 경우는 Fail count 칸에 빨간 점멸등 아이콘으로 표시가 되고, 이를 JIRA에 보고합니다. Shell test의 경우에는 core를 자동으로 보고하는 기능이 탑재되어 있습니다.
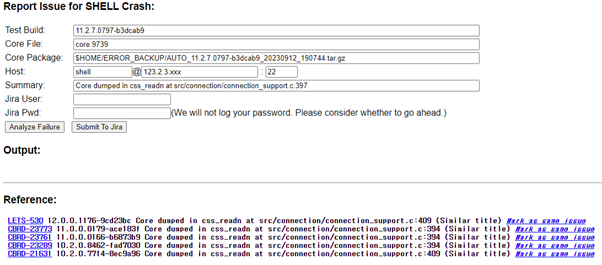
shell test core report 화면
셋째로, 장비 환경에 문제가 있는 경우입니다. 장비 설정을 잘못 설정한 채로 테스트가 돌아가게 되면 해당 장비에서 실행된 테스트케이스들은 fail이 발생합니다. 이러한 경우는 설정을 올바르게 해주고 다시 실행하면 정상적인 결과가 도출됩니다.
위와 같이 QA home에서 fail결과를 발견할 때는 상황을 분석하여 JIRA에 보고하거나 구두로 담당 개발자에게 해당 내용을 정리해서 전달합니다.
1-2) Performance test
다음은 Performance test의 결과 페이지입니다.
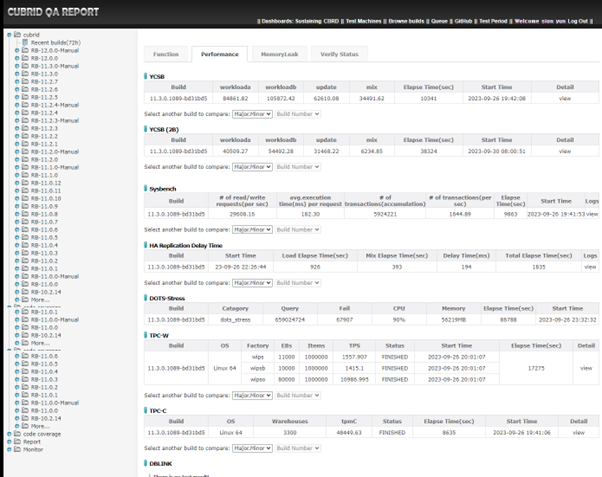
QAhome Performance 결과 화면
Performance test는 CUBRID 데이터베이스 시스템의 성능을 측정하고 버전 별로 비교하는 데에 의의가 있으며, 사용되는 일반적인 작업 부하를 시뮬레이션하고 각 시스템이 이러한 부하에서 어떻게 수행되는지를 측정하여 평가합니다. Functional test와 마찬가지로, 성능에 문제가 있는 것으로 보일 경우 JIRA에 보고합니다.
신규 기능뿐만 아니라 기존 기능에 대해서도 품질을 유지하는 것이 중요하기 때문에 Regression test의 결과를 유지 및 관리하고 분석하는 업무는 매우 중요합니다. 앞서 설명했듯이, 기존 동작에 문제가 생겼다면 원인을 파악하고 개발팀과 논의하여 문제를 해결합니다.
1-3) Code coverage
QA home에 탑재된 다양한 테스트들은 소프트웨어 품질 지표인 코드 커버리지 테스트로 관리되고 있습니다. 코드 커버리지는 현재의 테스트들로 전체 소스코드가 얼마나 수행되고 있는지에 대한 수치를 나타내며, QA팀에서는 커버리지 수치를 유지 및 향상시키는 노력을 하고 있습니다. 다음은 코드 커버리지 테스트의 수행 결과 페이지이며, 항목별로 간단히 설명 드리도록 하겠습니다.
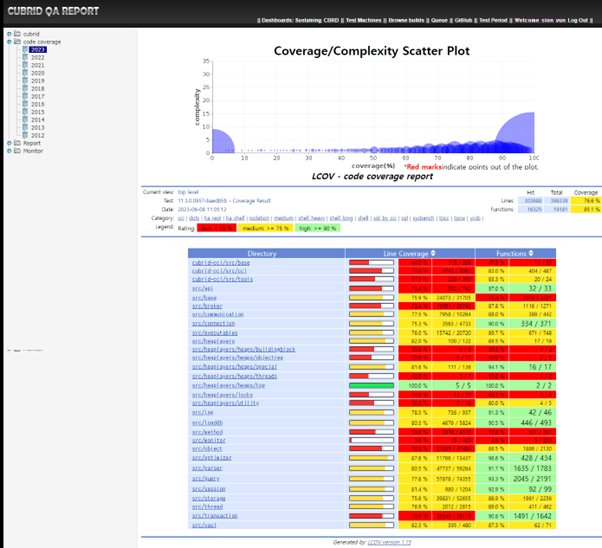
QAhome code coverage 화면

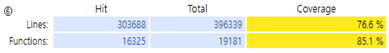
① Current view : top level
현재 수행된 커버리지 테스트는 top level커버리지이며, 이는 프로그램 또는 모듈 전체에서 코드가 얼마나 실행되었는지를 나타내는 메트릭 중 하나입니다.
② Test: 11.3.0.0957-baed85b 빌드 버전으로 Coverage Test를 수행한 결과를 의미합니다.
③ Date: 테스트가 끝난 시점을 의미합니다.
④ Category: 커버리지 테스트에 사용된 테스트들의 리스트이며, 각각의 테스트를 클릭하면 해당 테스트에서의 커버리지 수치를 볼 수 있습니다.
⑤ Legend: code coverage report에서 사용된 색상에 대한 설명입니다. 75%미만은 빨강, 75%이상은 노랑, 90%이상은 연두색으로 표현되어 있습니다.
⑥ 커버리지 테스트에서 “Hit”는 일반적으로 특정 코드 또는 프로그램의 실행 경로에 따라 어떤 코드 블록, 라인, 함수 등이 실행되었음을 나타냅니다. 위 커버리지 테스트에서 Hit한 코드라인의 개수는 총 303688입니다.
2. CTP (CUBRID Test Program)
CTP는 CUBRID의 function test들을 수행하기 위해 만들어진 테스트 툴입니다. SQL/MEDIUM/SQL_BY_CCI, Shell, HA_repl, Isolation, RQG, Unit test, JDBC, Code Coverage 등의 테스트들을 수행할 수 있고, git clone을 통해 CTP를 다운로드 받을 수 있습니다.
가이드 문서를 참조하여 장비 설정 후, 테스트를 수행할 수 있습니다. (각 테스트들의 가이드 문서는 https://github.com/CUBRID/cubrid-testtools/tree/develop를 참조). CTP에 대해서는 추후 더 자세하게 소개하도록 하겠습니다.
이처럼 CUBRID QA팀은 기본적으로 QA home, CTP를 통해 업무를 진행하고, Git, Jira를 이용하여 전체 프로젝트를 관리하고 있습니다.
마무리하며
지금까지 CUBRID QA팀의 업무 방식 및 검증 프로세스를 간단하게 소개했습니다. “품질은 QA 전문가의 노력만으로 높아지지 않는다.”라는 말이 있습니다. 품질을 향상시키고, 좋은 제품을 제공하기 위해서는 모든 구성원이 협력해야 합니다. CUBRID는 모든 구성원이 버그 리포팅 및 버그 수정을 하고 있으며, 품질 향상에 기여하는 일에 협력하고 있습니다. QA팀도 다양한 QA활동을 통해 단순히 테스트를 하는 것이 아닌, 정확한 요구사항 분석에 기반한 품질 높은 제품을 만들어 나가도록 노력하겠습니다.
 Visual Studio Code 소개
Visual Studio Code 소개
 CUBRID의 개발 문화: CUBRID DBMS 프로젝트 빌드 가이드와 빌드 ...
CUBRID의 개발 문화: CUBRID DBMS 프로젝트 빌드 가이드와 빌드 ...